



Hi Everyone!
Welcome back to part 2 of how I built Blokfeed. In my previous article I covered why I built Blokfeed, but now let's get into the how.
Let's jump right in... 🚴♂️
Before I could start building out the features for Blokfeed I had to get data. Luckily many news sources use RSS (Really Simple Syndication) feeds to syndicate their articles. Which means I simply need to poll the RSS feeds for the latest news articles.
Awesome - I have a way to collect news articles... Next question how often do I want to pull articles and how am I going to schedule this? 💡 AWS Lambdas. Lambdas have the ability to run on a schedule which allows me to determine the frequency of data collection. Perfect. Let's get coding.
I personally use the Serverless Framework to help spin up lambdas. You can find more information on their site.
Now that I have a framework I started working on a parser for the rss feed... I Found this rss-parser soon after starting to help with the parsing.
Ok - building blocks are in place... let's diagram what I am going to build to start aggregating news articles.
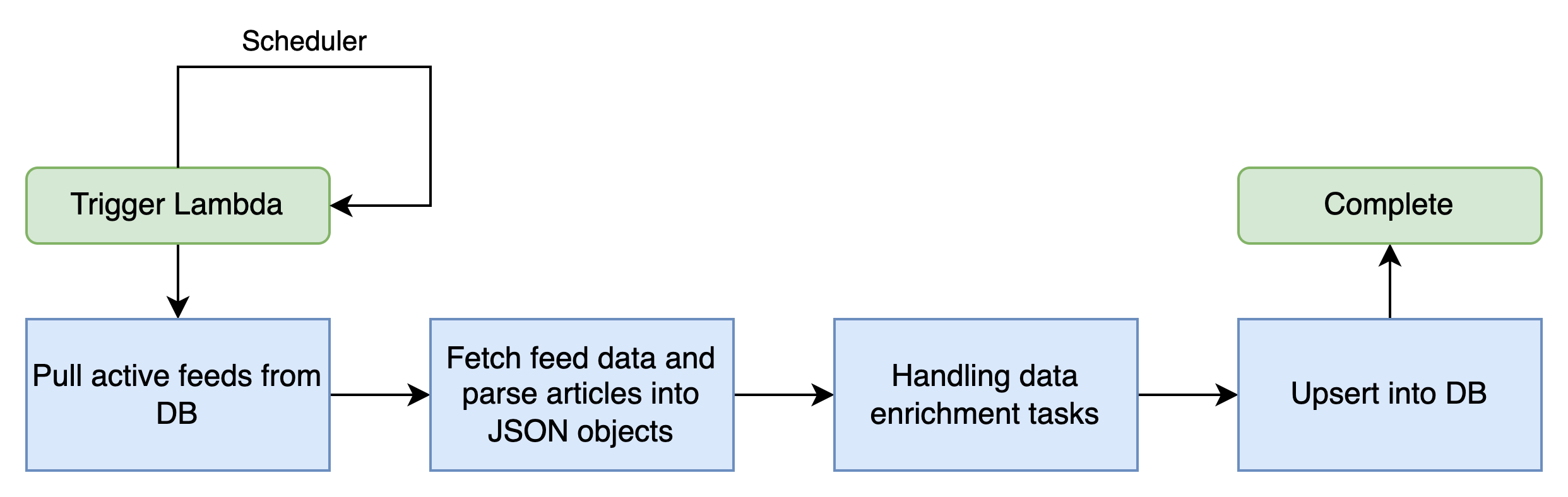
As you can see it's a fairly straight forward ETL process where we fetch (extract) the data from the RSS feeds, process (transform) and upsert (load) into our DB.
While transforming the RSS feed data into a structure Blokfeed uses, I enriched the data for monitoring and filtering purposes.
Following the data transformation, I upsert the article information meaning the system will either update or insert a record depending on various conditions. An easy way to do this is to create a hashId which would be unique to that article.
There you have it - a simple ETL process to start collecting news articles.
What's next? 🤔 I have articles, how am I going to view them?
Part 3 - Building a website to view articles.
Let me know in the comments what you think of these overviews?
Interested in code? If there is enough interest I can start working on examples of how you can build a similar ETL process using AWS Lambdas.